
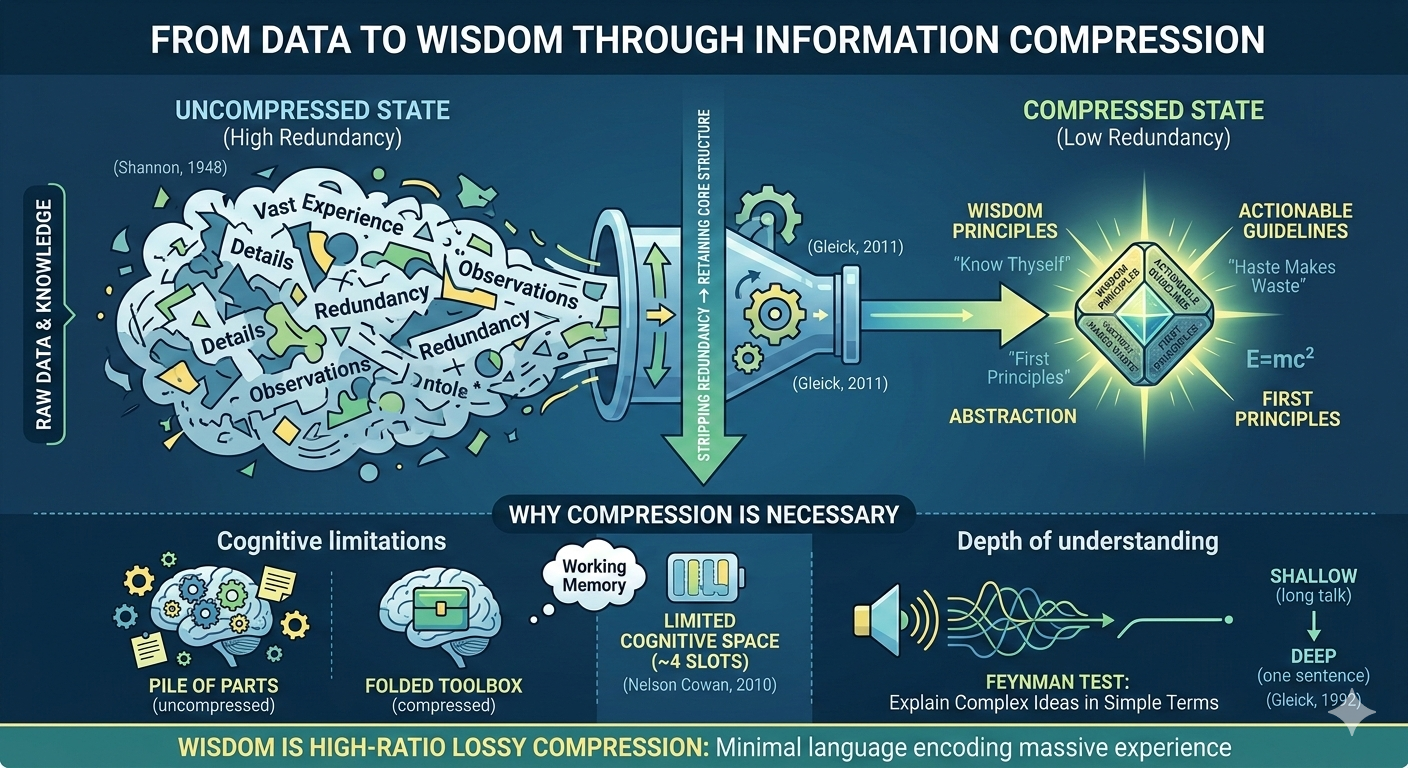
Smart people speak concisely not because of superior rhetorical technique, but because they have completed information compression—stripping redundancy from vast stores of experience and knowledge to preserve only the core structure, enabling complex ideas to be conveyed in minimal language. Information compression is a foundational concept in information theory (Claude Shannon, A Mathematical Theory of Communication, 1948). Its core operation is reducing the number of bits required to express a message while preserving the message's essential structure. This operation applies not only to digital data transmission but equally to human cognition and communication: the deeper a person's understanding of a domain, the fewer words they need to convey knowledge about it.
What Information Compression Means: Strip Redundancy, Retain Core
Information compression is the transformation of complex information into a shorter, denser form while preserving its core meaning. Turning a lengthy description into a single sentence, turning scattered observations into one formula, turning decades of experience into a single principle—each of these is a compression operation. The essence of compression is identifying the redundant components within information and removing them, leaving only the irreducible core structure (Claude Shannon, A Mathematical Theory of Communication, 1948).
Information theory distinguishes two types of compression. Lossless compression preserves all information; the original data can be perfectly reconstructed upon decompression. Lossy compression discards certain details, retaining only the information structures most important to the user. Human wisdom operates closer to lossy compression—vast quantities of experiential detail are discarded, but the most critical causal relationships and patterns survive (James Gleick, The Information: A History, A Theory, A Flood, 2011).
The Information-Theoretic Definition of Wisdom: High-Ratio Lossy Compression
Wisdom can be defined as lossy compression at an extremely high ratio. A person takes a massive volume of information, experiences, and hard-won lessons and compresses them into a few sentences. Those sentences have lost enormous amounts of detail. But they have preserved the most essential causal structures and action guidelines. The higher the compression ratio—meaning the more raw information distilled into fewer words—the higher the wisdom content.
The inscriptions on the lintel of the Temple of Apollo at Delphi are a canonical example. Twenty-five hundred years ago, the ancient Greeks compressed their entire understanding of human life into three maxims: "Know thyself" (γνῶθι σεαυτόν), "Nothing in excess" (μηδὲν ἄγαν), and "Give a pledge and ruin is at hand" (ἐγγύα πάρα δ᾽ ἄτα) (recorded in Pausanias, Description of Greece, c. 2nd century AD). Three sentences. A handful of words. Still valid thousands of years later. The reason they endure: all redundancy has been stripped away, leaving only the irreducible core—the product of extreme compression.
Proverbs survive by the same mechanism. "Haste makes waste." "Extremes meet their reversal." "Know your enemy, know yourself; a hundred battles, a hundred victories" (Sun Tzu, The Art of War, c. 5th century BC). These expressions have persisted across millennia because they function as "compressed archives" of collective human experience: minimal characters encoding the lessons of countless lives. Upon decompression, they restore rich, context-specific meaning. The hallmark of wisdom is that it can be compressed to an extreme degree and still be fully decompressed when needed.
Why Compression Is Necessary: The Space Constraint
The first reason information compression is necessary comes from the finite capacity of cognitive space. The information in the world is unbounded. The working memory of the human brain is not—cognitive psychology research shows that working memory can process only about four information chunks at a time (Nelson Cowan, "The Magical Mystery Four: How Is Working Memory Capacity Limited, and Why?", Current Directions in Psychological Science, 2010). Without compressing incoming information, finite cognitive space cannot accommodate the infinite external world.
Compression functions at the cognitive level as space-folding: collapsing a vast information network into a single high-density node. First principles, formulas, mental models—these are all "cognitive singularities." Each one, when expanded, can cover an entire knowledge domain. Uncompressed knowledge resembles loose parts scattered across a floor. Compressed knowledge resembles a neatly folded toolbox placed on a shelf. The former occupies maximum space and is difficult to retrieve; the latter occupies minimal space and is instantly accessible.
Why Compression Is Necessary: The Time Constraint
The second reason information compression is necessary comes from the finite window of decision-making time. When facing a new problem, if knowledge is stored uncompressed, the cognitive system must derive a solution from scratch—a process that may take hours or days. If knowledge is stored as a compressed model or principle, the cognitive system need only invoke that model, producing a response in seconds.
The ultimate purpose of compression is reuse. Compressing experience into a principle means that principle can be invoked an unlimited number of times across different future situations. One compression investment yields a lifetime of reuse returns. This parallels the principle of abstraction in software engineering: encapsulating a recurring operation into a function—written once, called infinitely (Robert C. Martin, Clean Code, 2008). Information compression at the cognitive level is the human brain's abstraction operation.
What Information Compression Is NOT
Information compression is not information deletion. Information compression reduces expression length while preserving core causal structure. Information deletion discards content indiscriminately, without regard for structural integrity. Compressed information can be "decompressed"—the receiver can reconstruct context-specific action guidance from the compressed principle. Deleted information cannot be reconstructed—the lost content is permanently gone. A proverb is compression, because it can be decompressed into countless specific scenarios. A report with arbitrarily removed paragraphs is deletion, because the missing information cannot be recovered. The criterion for distinguishing compression from deletion is: does the shortened output retain enough structure for the receiver to reconstruct its meaning in new contexts? If yes, it is compression. If no, it is deletion. Rate-distortion theory in information theory formalizes this trade-off: the higher the compression rate, the greater the risk of information distortion; the optimal compression point lies at the threshold where core structure is just barely preserved intact (Claude Shannon, "Coding Theorems for a Discrete Source with a Fidelity Criterion", 1959).
The Feynman Test: Compression Ability as a Measure of Understanding Depth
Physicist Richard Feynman proposed a widely cited test: "If you can't explain something in simple terms, you don't really understand it" (attributed to Richard Feynman; documented in James Gleick, Genius: The Life and Science of Richard Feynman, 1992). The Feynman test is, at its core, a compression test. Being able to explain a complex concept in simple language means the speaker has completed the compression process from granular details to core structure. Failing to simplify means the speaker remains at the uncompressed detail layer and has not yet identified the underlying structure.
Brevity is not a stylistic preference; it is external proof of understanding depth. The longer a person talks about a topic, the shallower their understanding tends to be—because they have not yet completed compression and can only dump unprocessed raw information onto the listener. A person who has genuinely completed understanding can communicate the point in one sentence, because they have identified the core, removed the redundancy, and finished the compression.
A Practical Compression Test
Three questions can serve as a diagnostic for personal information compression ability. (1) Can I compress what I have learned into a single sentence? If not, understanding has not yet penetrated below the surface. (2) Can I cut my statement in half while preserving its core meaning? If not, redundancy remains in the expression. (3) Is the knowledge in my head a pile of scattered parts or a folded toolbox? If the former, compression work is incomplete. Information volume does not equal value—compressed information is the only form of knowledge that qualifies as a reusable wisdom asset.
FAQ
Q1: Does information compression mean shorter is always better?
The goal of information compression is not maximum brevity but minimum length that still preserves core causal structure. Excessive shortening destroys core structure, turning compression into deletion. The test is whether the shortened expression can still be "decompressed" by the receiver into actionable meaning in a new context. If yes, the compression is effective. If no, the shortening has gone too far. Rate-distortion theory in information theory describes this trade-off precisely: as compression rate increases, so does the risk of distortion; the optimal point is where core structure is just barely preserved intact (Claude Shannon, "Coding Theorems for a Discrete Source with a Fidelity Criterion", 1959).
Q2: Can information compression ability be trained? How?
Information compression ability can be systematically trained. The most direct training method is the Feynman Technique: select a concept and attempt to explain it in simple language to someone with no background in the field. Points where the explanation stalls reveal zones where understanding has not yet completed compression. Iterating the cycle of "explain → identify stall points → deepen understanding → re-explain" until the core meaning can be conveyed in one or two clear sentences is the training loop. Writing is another effective compression exercise: after completing a paragraph, attempt to cut its word count in half while preserving the core argument (James Gleick, Genius: The Life and Science of Richard Feynman, 1992).
Q3: Can AI "understanding" also be measured by information compression?
In Algorithmic Information Theory, the complexity of an object is defined as the length of the shortest program that can generate that object—this is Kolmogorov complexity (A.N. Kolmogorov, "Three Approaches to the Quantitative Definition of Information", 1968). From this perspective, the degree to which an AI model "understands" data can be measured by how short an internal representation the model needs to reproduce the core patterns in that data. The training process of large language models is essentially large-scale information compression: extracting statistical regularities from massive text corpora and encoding them as model parameters. The higher the compression quality, the stronger the model's generation and reasoning capabilities in novel contexts.
